ComfyUI_examples
unCLIP Model Examples
unCLIP models are versions of SD models that are specially tuned to receive image concepts as input in addition to your text prompt. Images are encoded using the CLIPVision these models come with and then the concepts extracted by it are passed to the main model when sampling.
It basically lets you use images in your prompt.
Here is how you use it in ComfyUI (you can drag this into ComfyUI to get the workflow):
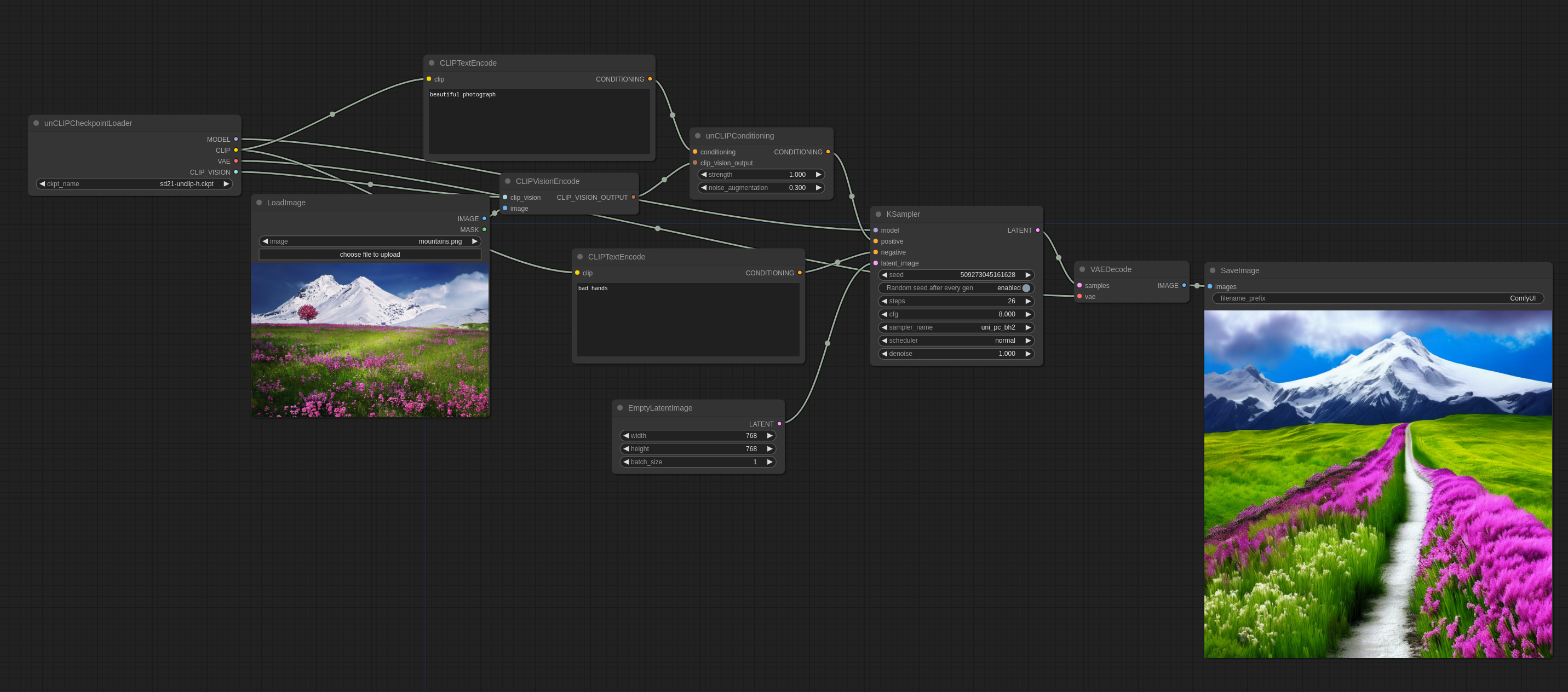
noise_augmentation controls how closely the model will try to follow the image concept. The lower the value the more it will follow the concept.
strength is how strongly it will influence the image.
Multiple images can be used like this:
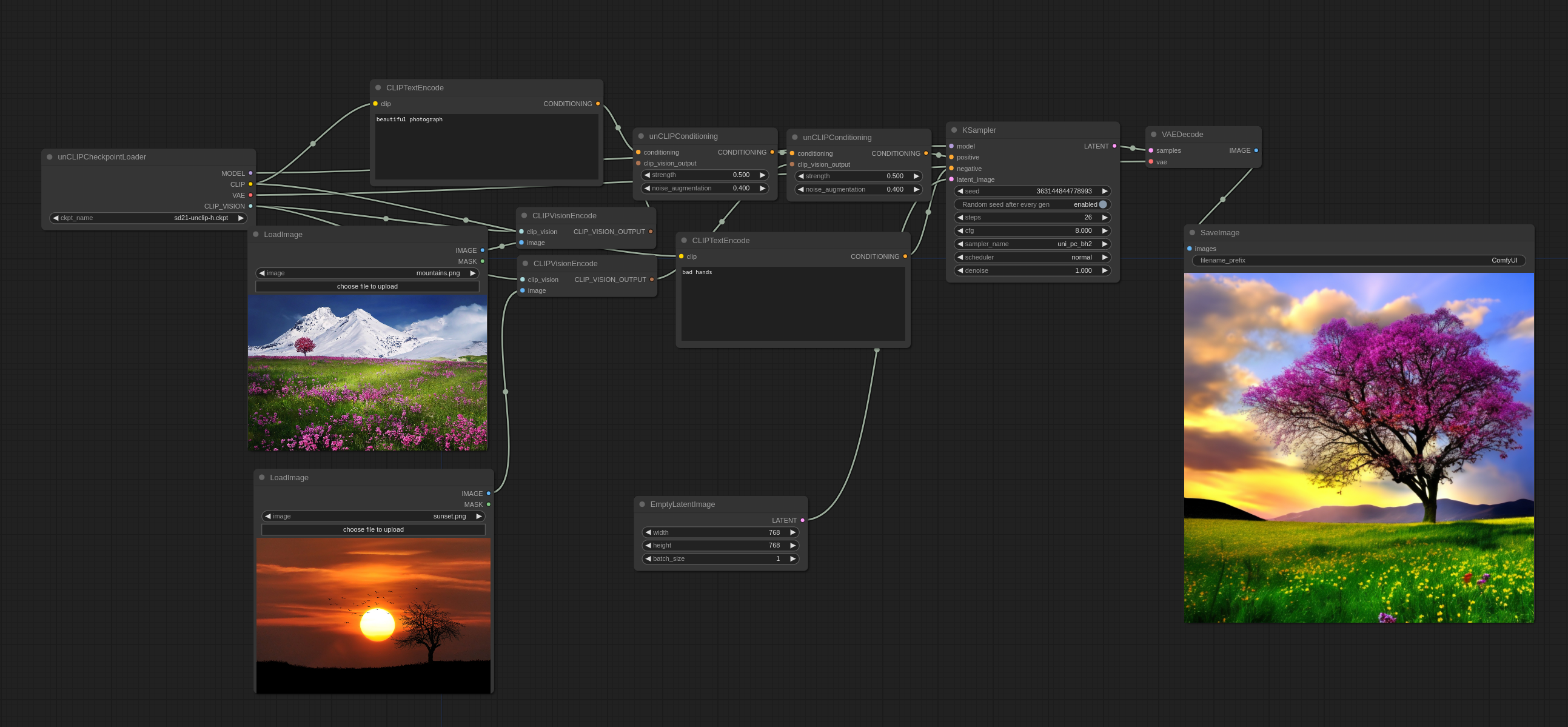
You’ll notice how it doesn’t blend the images together in the traditional sense but actually picks some concepts from both and makes a coherent image.
Input images:


You can find the official unCLIP checkpoints here
You can find some unCLIP checkpoints I made from some existing 768-v checkpoints with some clever merging here (based on WD1.5 beta 2) and here (based on illuminati Diffusion)
More advanced Workflows
A good way of using unCLIP checkpoints is to use them for the first pass of a 2 pass workflow and then switch to a 1.x model for the second pass. This is how the following image was generated. (you can load it into ComfyUI to get the workflow):
